| 模型监控指标 | 您所在的位置:网站首页 › psi 计算公式 › 模型监控指标 |
模型监控指标
|
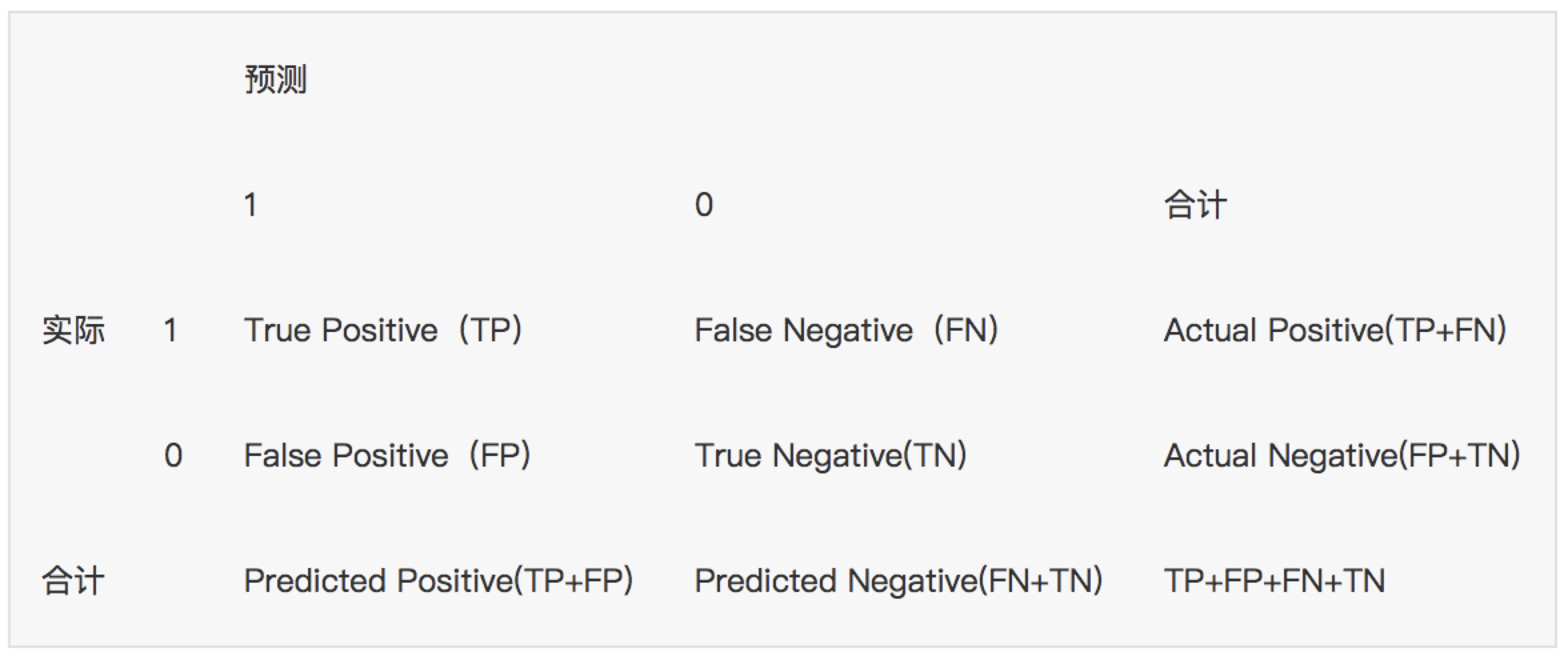
1. 混淆矩阵 确定截断点后,评价学习器性能 假设训练之初以及预测后,一个样本是正例还是反例是已经确定的,这个时候,样本应该有两个类别值,一个是真实的0/1,一个是预测的0/1
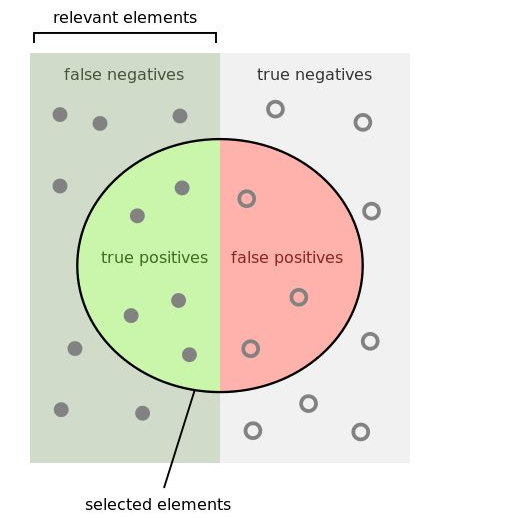
TP(实际为正预测为正),FP(实际为负但预测为正),TN(实际为负预测为负),FN(实际为正但预测为负) 通过混淆矩阵我们可以给出各指标的值:查全率(召回率,recall):样本中的正例有多少被预测准确了,衡量的是查全率,预测对的正例数占真正的正例数的比率: 查全率=检索出的相关信息量 / 系统中的相关信息总量 = TP / (TP+FN) 查准率(精准率,Precision):针对预测结果而言,预测为正的样本有多少是真正的正样本,衡量的是查准率,预测正确的正例数占预测为正例总量的比率:查准率=正确预测到的正例数/实际正例总数 = TP / (TP+FP) 准确率(Accuracy):反映分类器统对整个样本的判定能力,能将正的判定为正,负的判定为负的能力,计算公式: 准确率=(TP+TN) / (TP+FP+TN+FN) 评分卡准确率如下:
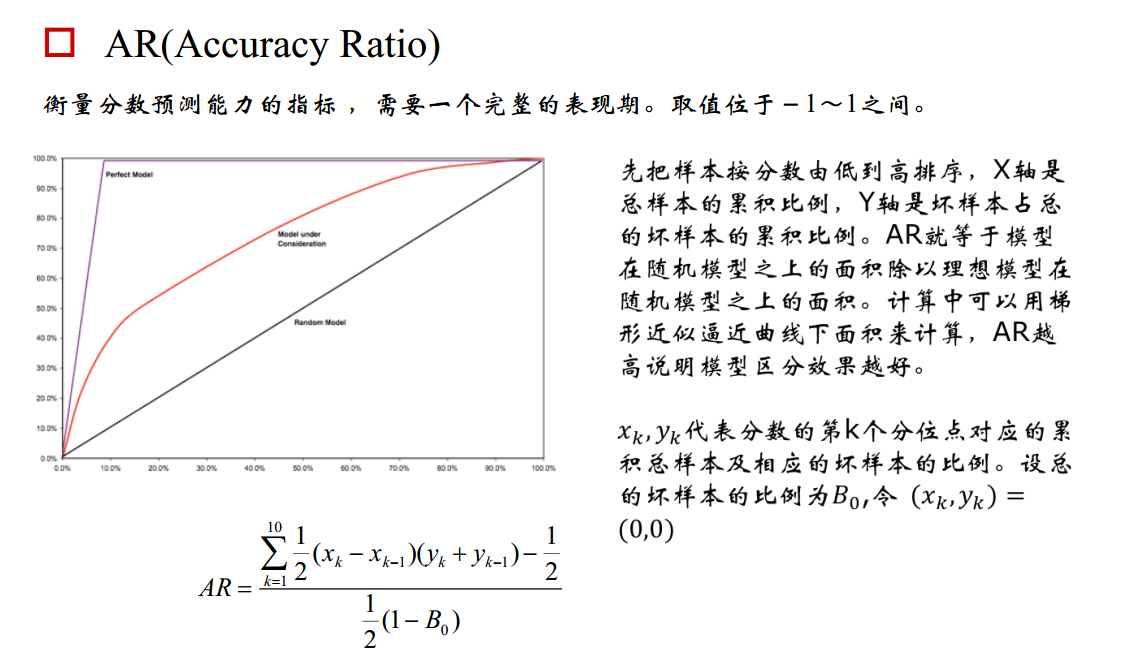
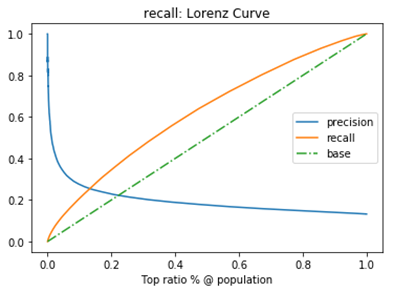
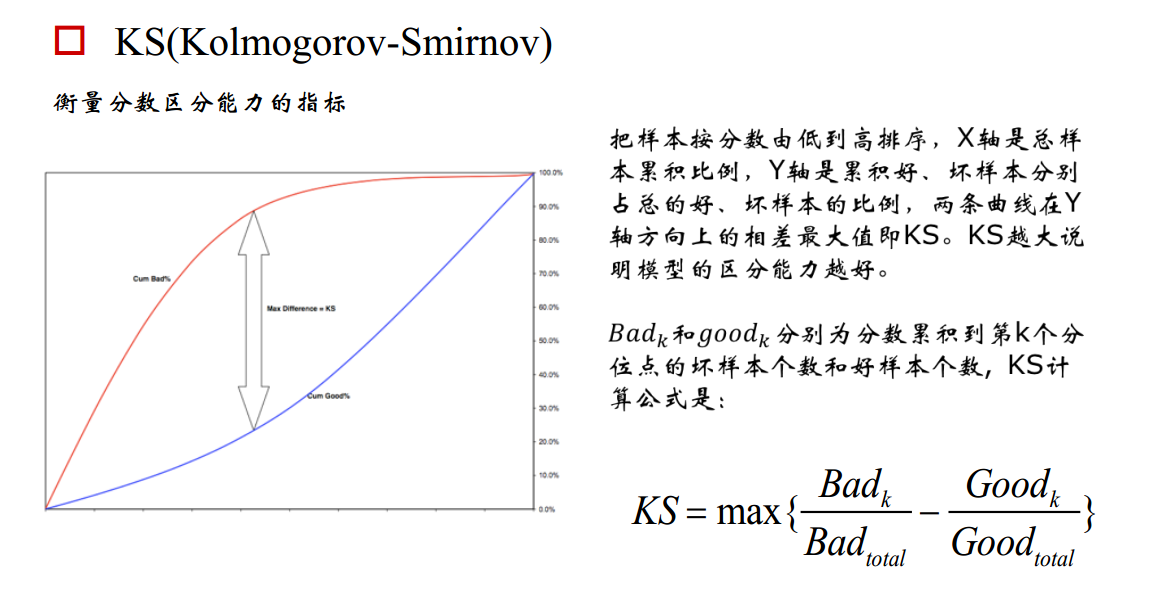
阴性预测值(NPV):可以理解为负样本的查准率,阴性预测值被预测准确的比例,计算公式: 阴性预测值=正确预测到的负例数/实际负例总数=TN / (TN+FN) 查准率和查全率通常是一对矛盾的度量,通常一个高,另外一个就低。两个指标都很重要,我们应该如何综合考虑这两个指标呢?主要有两种办法:1. "平衡点“ Break-Even Point, BEP查准率=查全率的点,过了这个点,查全率将增加,查准率将降低。如下图,蓝色和橘黄色的交叉点就是“平衡点” 2. F1度量---查准率和查全率的加权调和平均数(1)当认为查准率和查全率一样重要时,权重相同时: (2)当查准率查全率的重要性不同时,即权重不同时:通常,对于不同的问题,查准率查全率的侧重不同。比如,对于商品推荐系统,为了减少对用户的干扰,查准率更重要;逃犯系统中,查全率更重要。因此,F1度量的一般形式: 其中β表示查全率与查准率的权重,很多参考书上就只给出了这个公式,那么究竟怎么推导来的呢?两个指标的设置及其关系如下,因为只考虑这两个指标,所以二者权重和为1,即 可以推导得到 带权重的调和平均数公式如下: 进一步推导: 因此1. β=1,查全率的权重=查准率的权重,就是F12. β>1,查全率的权重>查准率的权重3. β利用ROC曲线下的面积(AUC,area under ROC curve,是一个数值)进行比较。 3. KS曲线,KS值 学习器将正例和反例分开的能力,确定最好的“截断点”KS曲线和ROC曲线都用到了TPR,FPR。KS曲线是把TPR和FPR都作为纵坐标,而样本数作为横坐标。 作图步骤:1. 根据学习器的预测结果(注意,是正例的概率值,非0/1变量)对样本进行排序(从大到小)-----这就是截断点依次选取的顺序2. 按顺序选取截断点,并计算TPR和FPR ---也可以只选取n个截断点,分别在1/n,2/n,3/n等位置3. 横轴为样本的占比百分比(最大100%),纵轴分别为TPR和FPR,可以得到KS曲线4. TPR和FPR曲线分隔最开的位置就是最好的”截断点“,最大间隔距离就是KS值,通常>0.2即可认为模型有比较好偶的预测准确性例图:
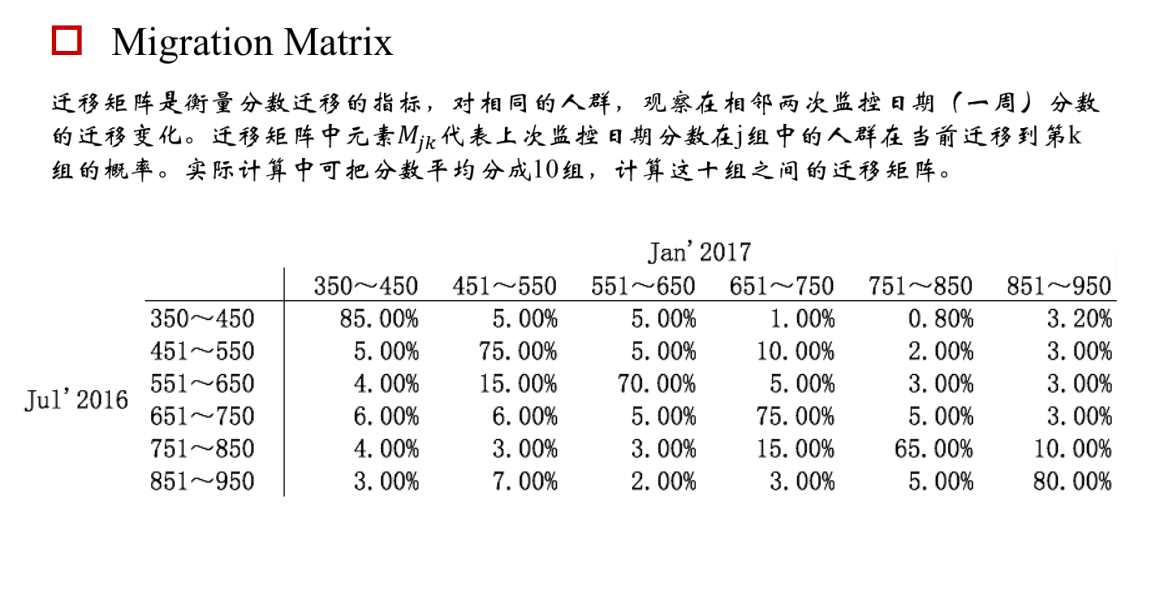
作为评分卡模型性能监测指标,在模型构建初期KS基本要满足在0.3以上,而在评分卡模型监测期间,通常以日、周和月为维度进行计算KS,观察评分卡对好坏客户的区分能力是否仍然保持建模时候的状态。如果KS持续下降恶化,就要考虑是市场发生了变化所致,还是客群发生了偏移,还是说评分卡模型不够稳定,或者是评分卡内的某个特征变量发生重大变化所致。如果KS下降至阈值之下,而无法通过重新训练模型进行修正的话,就要考虑上新的评分卡模型代替旧的版本。不仅评分卡模型整体分数要进行KS的监测,模型内的每个特征变量同样要进行KS监测,这样就能立即发现究竟是模型整体发生恶化,还是单一某个特征变量区分能力在恶化。如果仅仅是单一某个特征变量区分能力在恶化的话,可以考虑更换特征变量或者剔除特征变量的方法进行修正。 4.psi
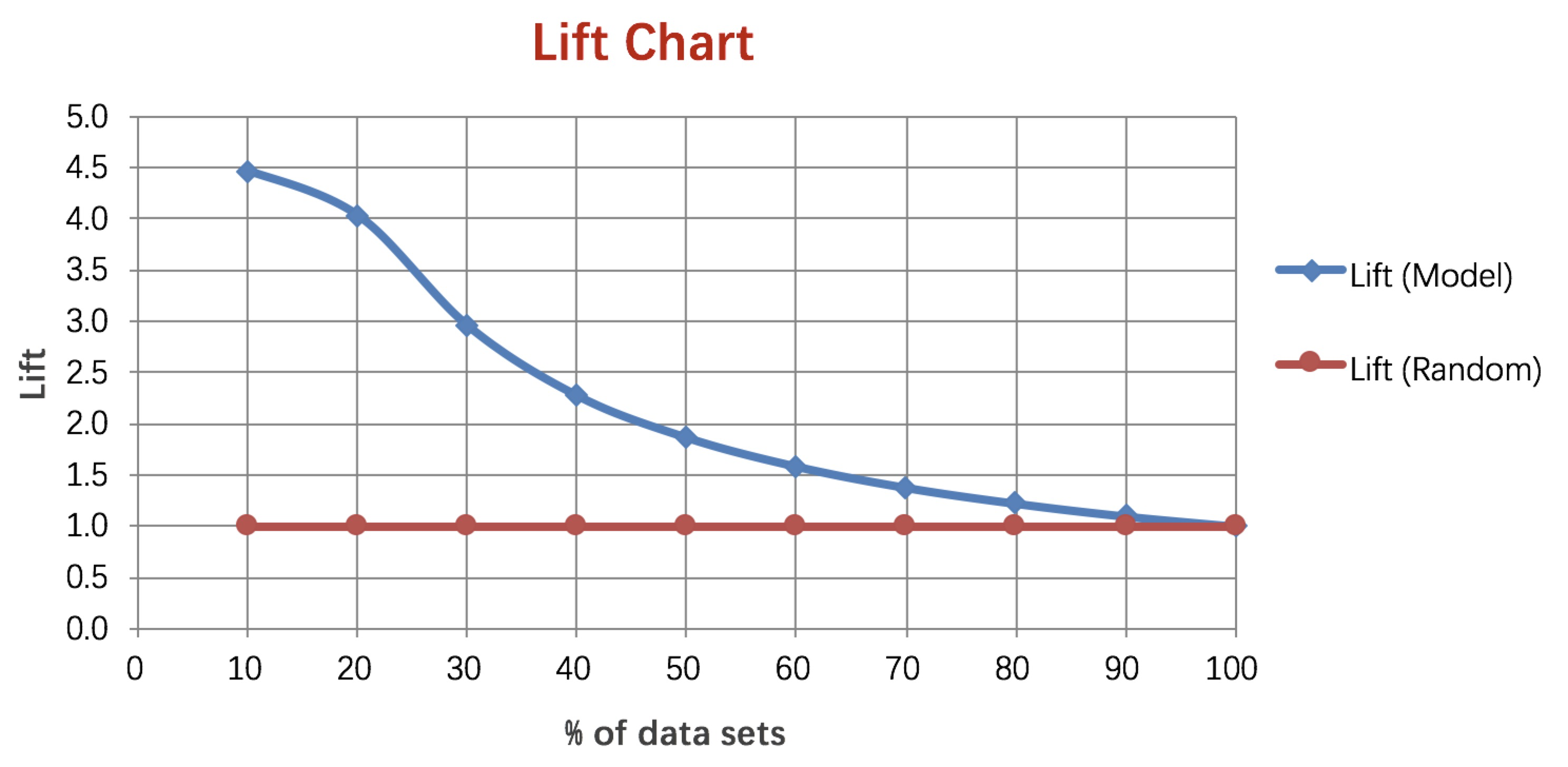
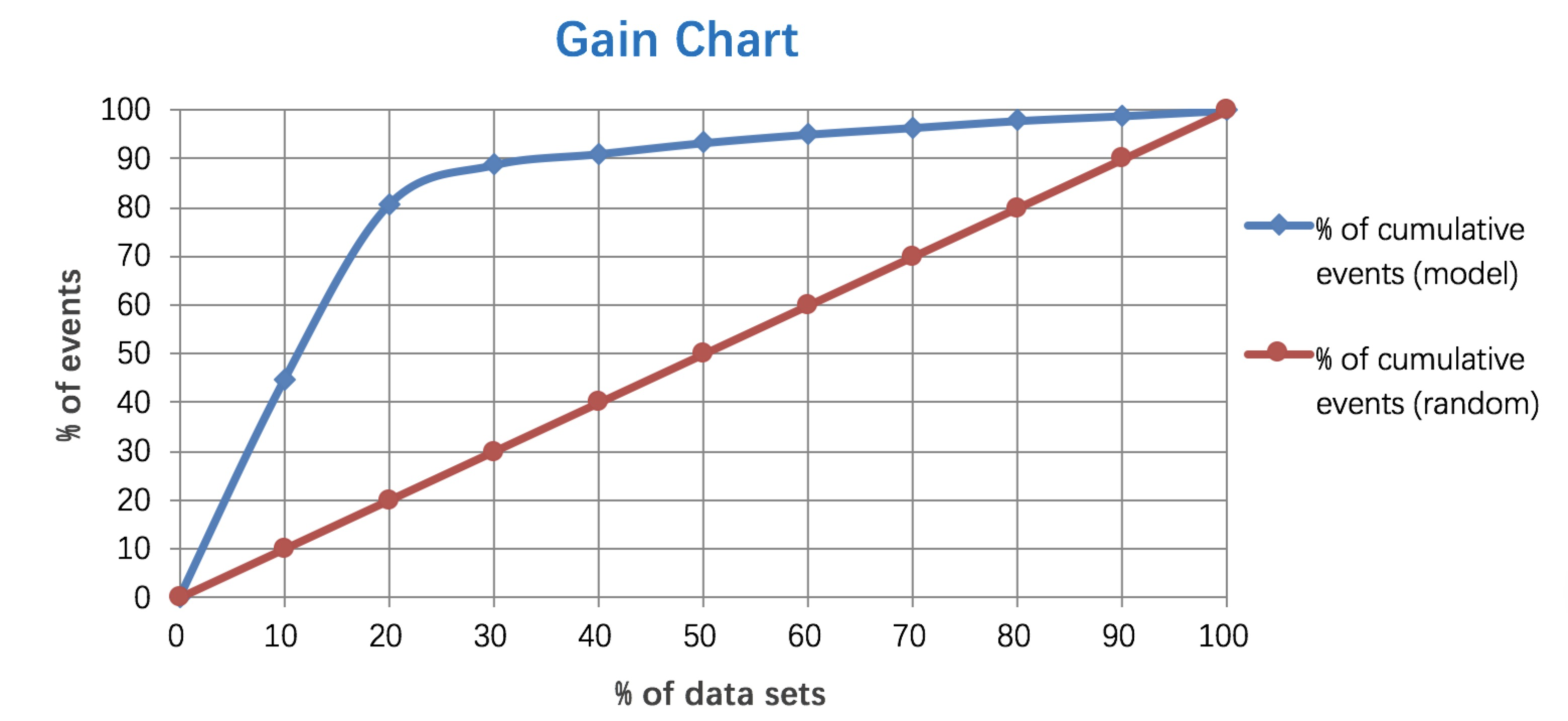
psi = sum((实际占比-预期占比)/ln(实际占比/预期占比)) 举个例子解释下,比如一个评分卡模型,按天为维度计算PSI,我们把模型刚上线第一天(设定为一个基期)的各分数段用户占比作为预期占比P1,之后每天的各分数段用户占比作为实际占比P2,这样根据公式就可以计算出每天的PSI值,通过观测这些PSI的大小和走势,从而实现对评分卡稳定性的监测。通常PSI会以日、周和月为维度进行计算,同时也会对评分卡模型中各个特征变量分别做PSI监测。一般认为PSI小于0.1时候模型稳定性很高,0.1-0.25一般,大于0.25模型稳定性差,建议重做。 模型分数的变化可能由特征变化引起,也可能是模型本身不稳定引起,若是高分段总数量没变,而psi值变动较大,认为需要重训模型。若是psi值没变,高分段总数量变多,认为整体用户变好。 5. Lift 和Gain图Lift图衡量的是,与不利用模型相比,模型的预测能力“变好”了多少,lift(提升指数)越大,模型的运行效果越好。 Gain图是描述整体精准度的指标。计算公式如下: 作图步骤:1. 根据学习器的预测结果(注意,是正例的概率值,非0/1变量)对样本进行排序(从大到小)-----这就是截断点依次选取的顺序2. 按顺序选取截断点,并计算Lift和Gain ---也可以只选取n个截断点,分别在1/n,2/n,3/n等位置例图:
6.KT 值
|
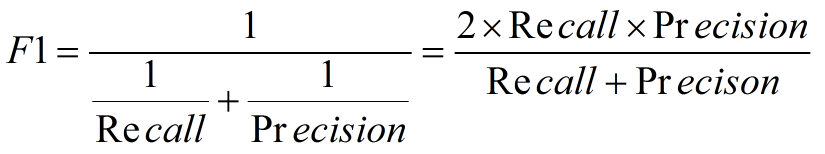


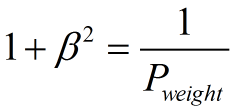
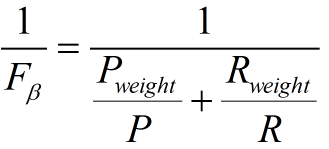
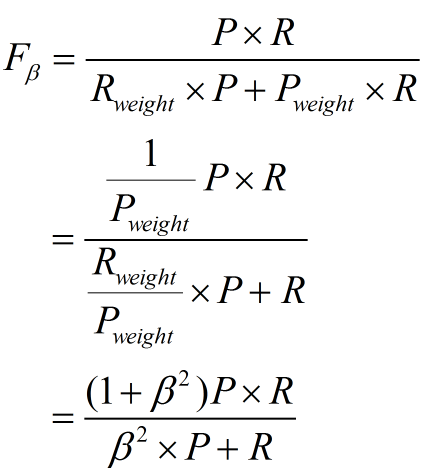


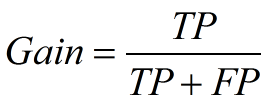

【本文地址】